🔥[2026-03-16] Introducing HalDec-Bench, which evaluates the VLM's ability to detect hallucinations in captions ! 🚀
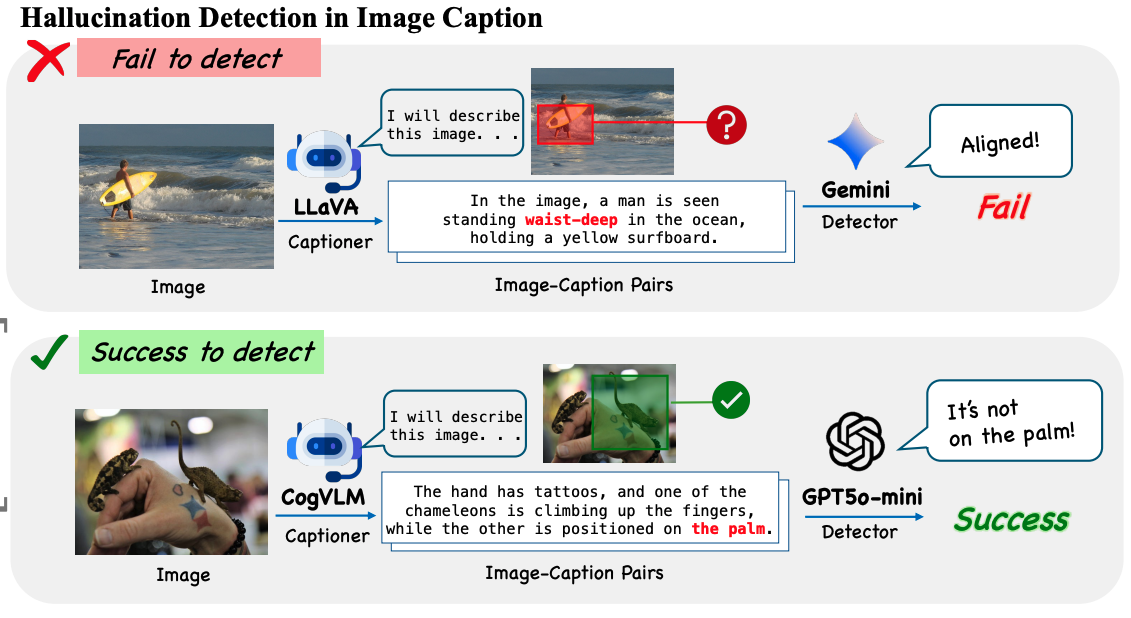
Hallucination detection in captions (HalDec) assesses a vision-language model’s ability to correctly align image content with text by identifying errors in captions that misrepresent the image.
Beyond evaluation, effective hallucination detection is also essential for curating high-quality image-caption pairs used to train VLMs.
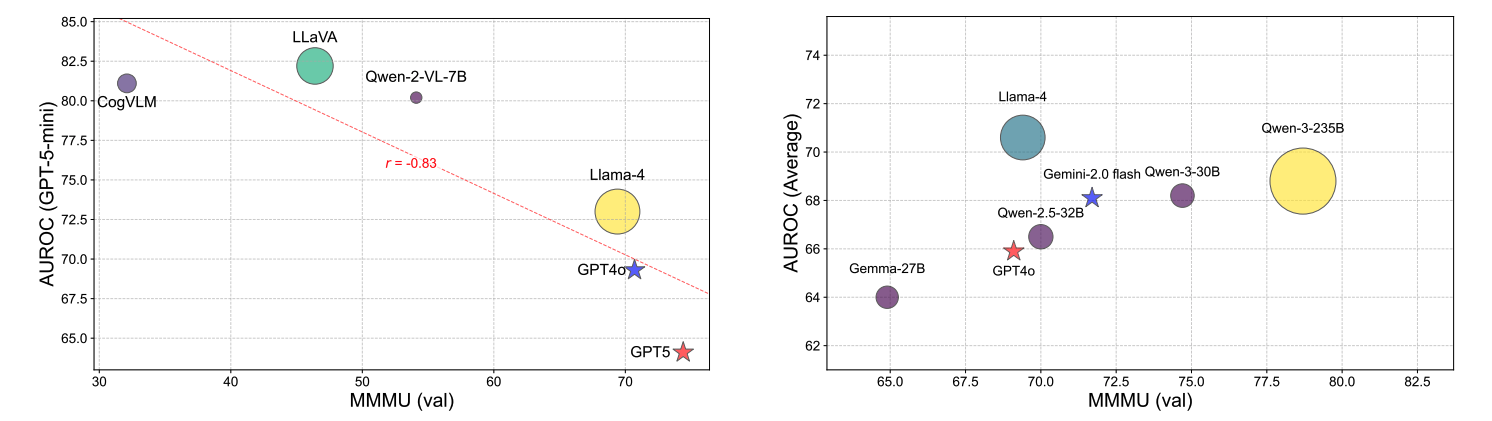
However, the generalizability of VLMs as hallucination detectors across different captioning models and hallucination types remains unclear due to the lack of a comprehensive benchmark.
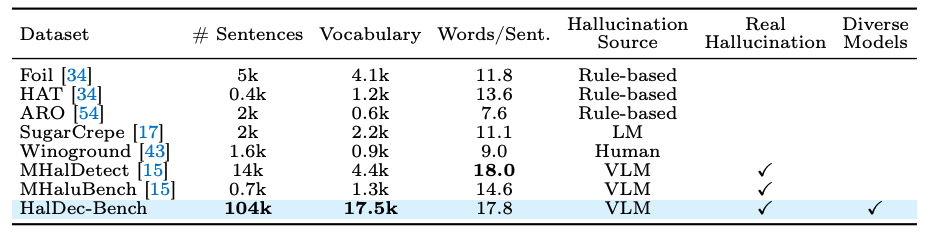
In this work, we introduce HalDec-Bench, a benchmark designed to evaluate hallucination detectors in a principled and interpretable manner.
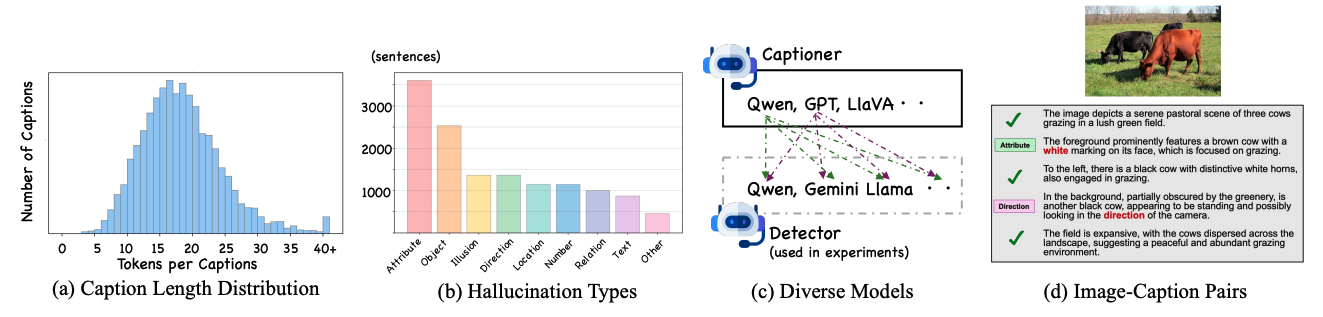
HalDec-Bench contains captions generated by diverse VLMs together with human annotations indicating the presence of hallucinations, detailed hallucination-type categories, and segment-level labels.
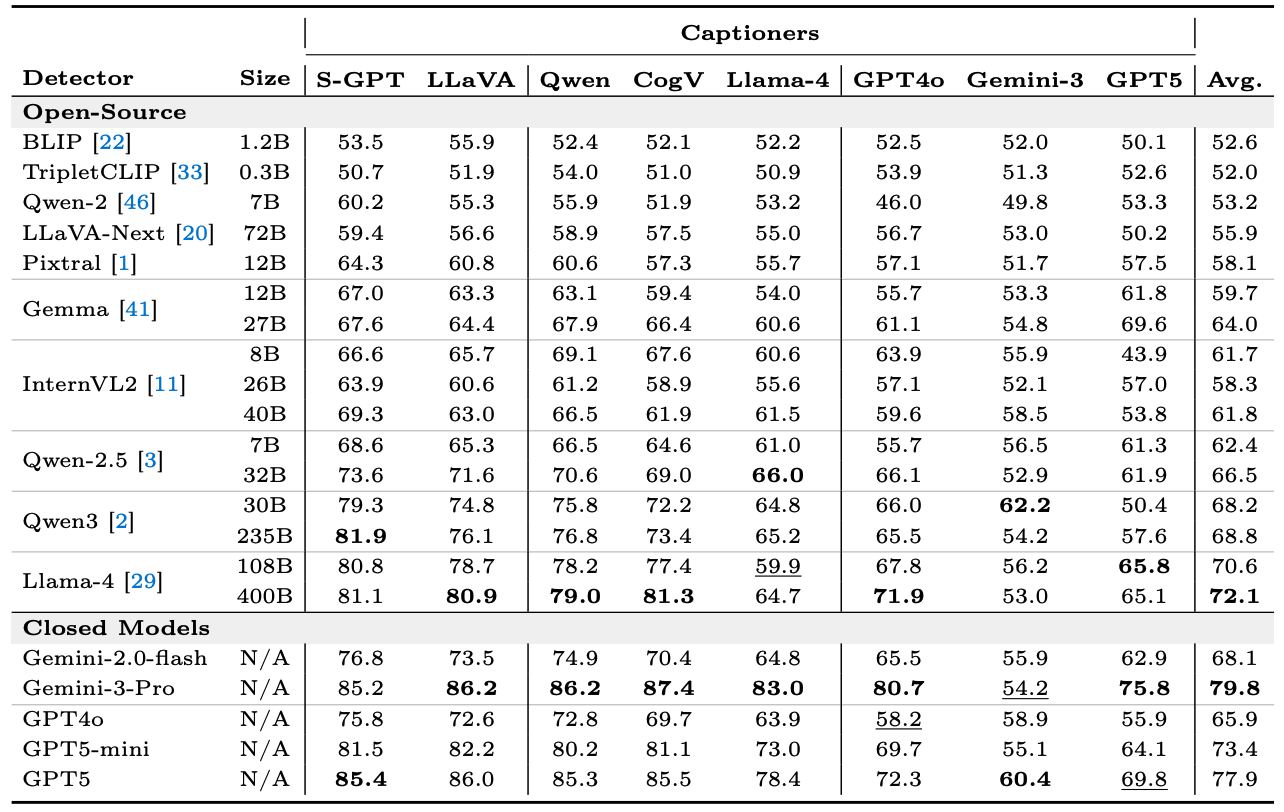
The benchmark provides tasks with a wide range of difficulty levels and reveals performance differences across models that are not visible in existing multimodal reasoning or alignment benchmarks. Our analysis further uncovers two key findings.
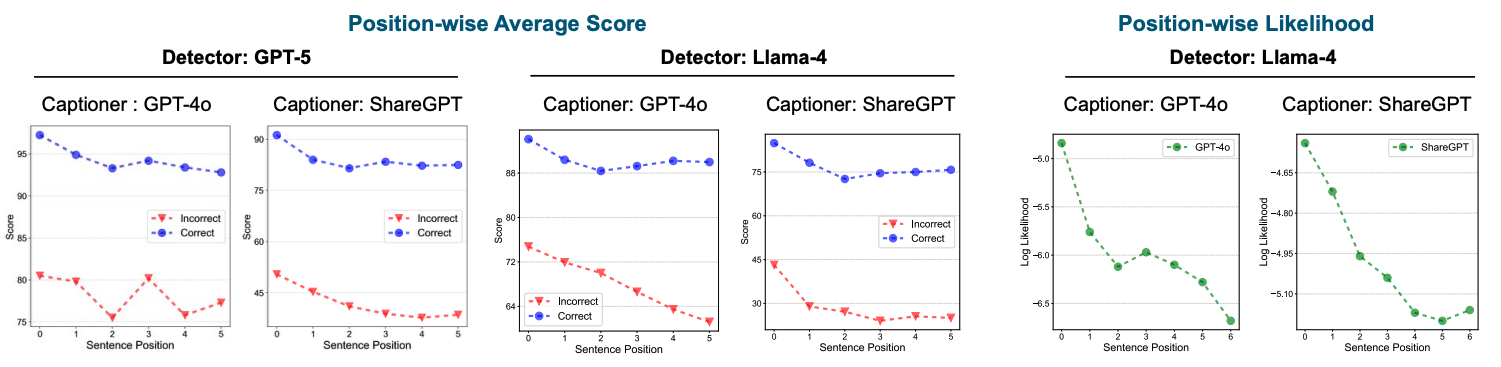
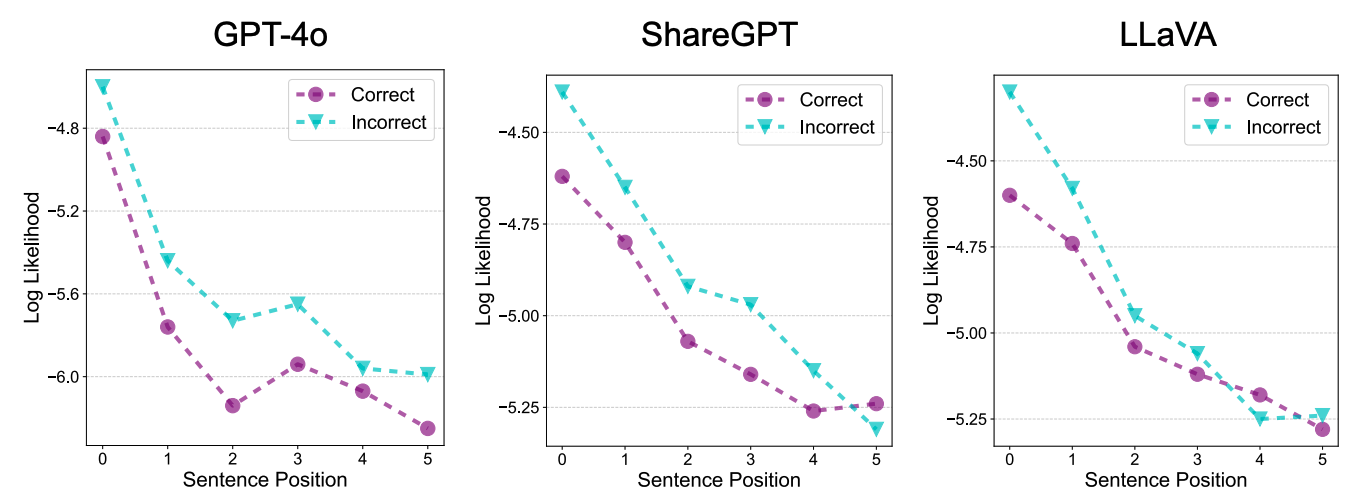
First, detectors tend to recognize sentences appearing at the beginning of a response as correct, regardless of their actual correctness.
Second, our experiments suggest that dataset noise can be substantially reduced by using strong VLMs as filters while employing recent VLMs as caption generators.